
My Cuda Note 1: Intro
Published:
The photos and the examples are copied from CUDA Toolkit Documentation
Last modified: 2025-02-27
CUDA Introduction
GPU Arch
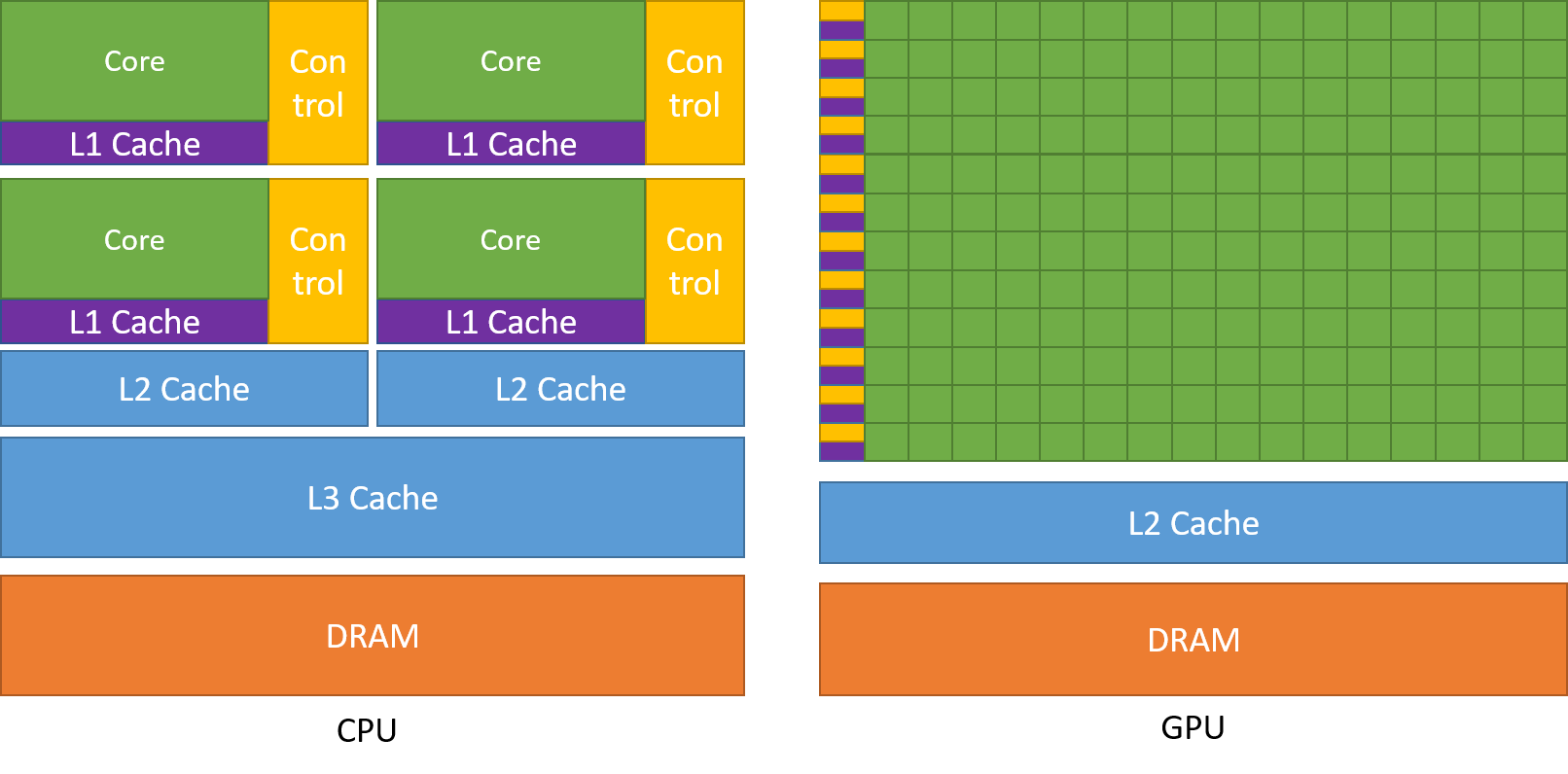
绿:Grids,执行线程Threads,大量的Cores使得并行性极高
每一横行:Streaming Multiprocessors (SMs)
一个SM通过若干个包括32个Threads的warp管理,采用SIMT (Single-Instruction, Multiple-Thread) 架构,各warp之间独立执行,一个warp执行同样的命令,如果一个warp间出现因数据满足不同的条件导致的分歧,warp会依次执行不同分支对应的操作,同时禁用其他分支的操作:
Example:
int tid = threadIdx.x;
if (tid % 2 == 0) {
...
} else {
...
}
首先进入第一个分支,偶数线程执行,奇数禁用,之后交换
多个Threads是组成block,一个block最多有1024个threads,即32个warps
Programming Model
1. Kernel
通过__global__函数前指定,调用时通过<<<…>>>表明需要多少个Thread执行,
Example:
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
VecAdd为定义的kernel,在调用时通过<<<1,N>>>表明需要1个有N个Thread的block执行
2. Thread
threadIdx:三维向量,因而可以最多支持到三维,可以通过_x,y,z_访问
Note: 只有传入的是dim3类型的才可以访问到合理的threadIdx.x/y/z, so as blockIdx
Example:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
传入为dim3类型的,因此可通过threadIdx.y访问
由于thread上级是block,如果传入的block数不为1,则需要调整索引:
Example:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
block数不为1,需要修改数组索引,blockIdx为block索引值,blockDim为一个block的线程数,因此该thread实际对应的数据索引为blockIdx.x * blockDim.x + threadIdx.x
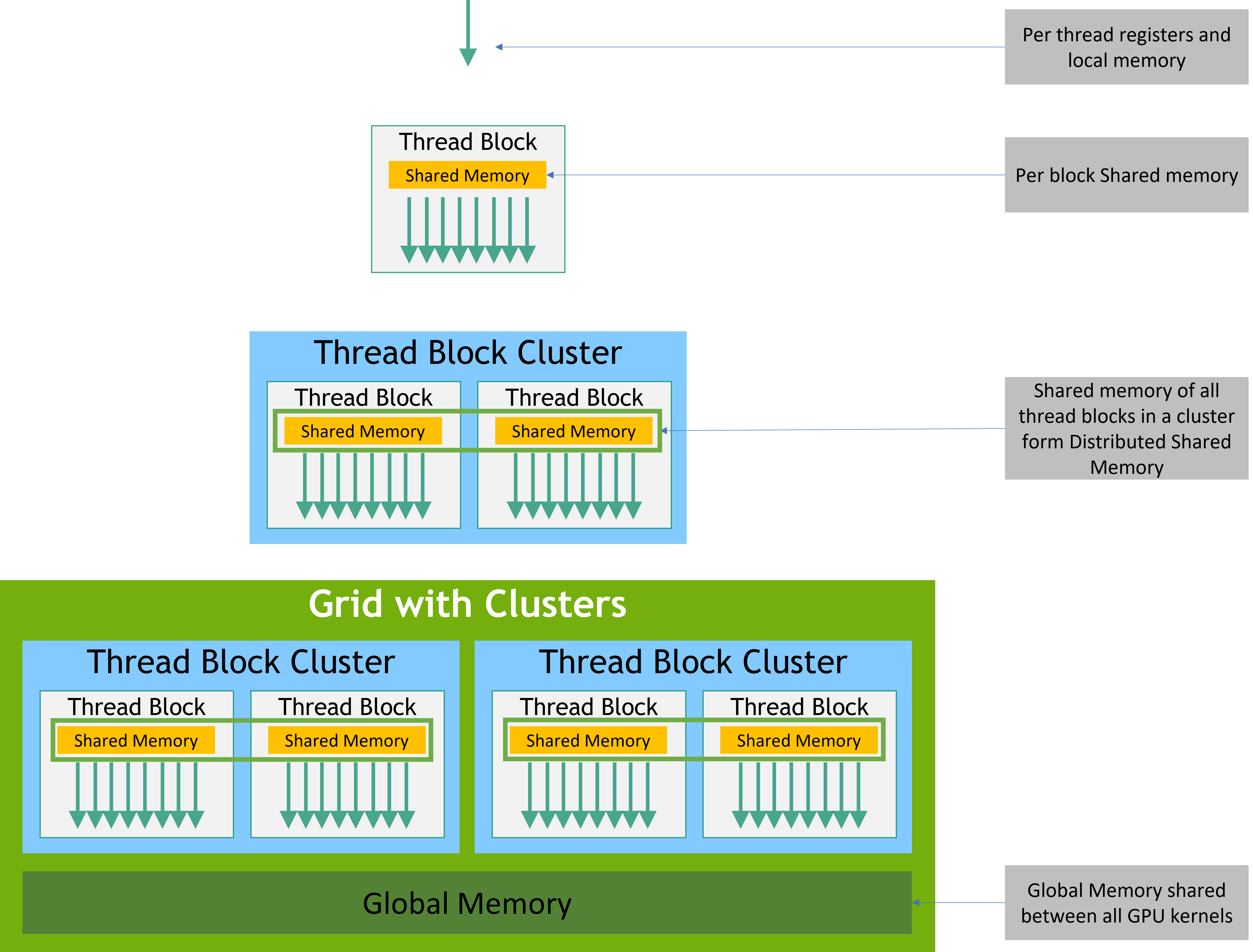
计算能力9.0限定:可以指定Thread Block Cluster,会有更好的调度性能
Example:
// Compile time cluster size 2 in X-dimension and 1 in Y and Z dimension
__global__ void __cluster_dims__(2, 1, 1) cluster_kernel(float *input, float* output)
{
...
}
// runtime set:
// No compile time attribute attached to the kernel
__global__ void cluster_kernel(float *input, float* output)
{
}
int main()
{
float *input, *output;
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
// Kernel invocation with runtime cluster size
{
cudaLaunchConfig_t config = {0};
// The grid dimension is not affected by cluster launch, and is still enumerated
// using number of blocks.
// The grid dimension should be a multiple of cluster size.
config.gridDim = numBlocks;
config.blockDim = threadsPerBlock;
cudaLaunchAttribute attribute[1];
attribute[0].id = cudaLaunchAttributeClusterDimension;
attribute[0].val.clusterDim.x = 2; // Cluster size in X-dimension
attribute[0].val.clusterDim.y = 1;
attribute[0].val.clusterDim.z = 1;
config.attrs = attribute;
config.numAttrs = 1;
cudaLaunchKernelEx(&config, cluster_kernel, input, output);
}
}
内存结构如下:
Next Post: How to build a Kernel in PyTorch.
Copyright:
This work is licensed under Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International![]()
![]()
![]()
![]()